- I. Rechercher les séquences des génomes de Listeria dans GENBANK
- II. Visualiser les fichiers de séquences
- III. Rechercher les gènes dans les séquences avec EMBOSS
- IV. Rechercher les "vrais" gènes avec BLAST
- V. Trouver de l'information sur les génomes avec GENBANK
- VI. Rechercher les gènes de virulence avec Artemis ACT
- VII. Visualisation de la structure 3D des protéines sélectionnées avec PDB et PyMol
II. Rechercher les séquences des génomes de Listeria dans GENBANK
GENBANK est une banque de données de séquences génétiques reconnue internationalement. Elle est maintenue aux Etats-Unis par le NCBI. On y trouve plus de 108 millions de séquences d'ADN publiquement disponibles. Le NCBI met également à la disposition de la communauté internationale de nombreux outils d'analyse de génome et un serveur de fichiers (FTP).
- Ouvrir un navigateur (firefox, ...) en cliquant sur l'icone du programme
- Se connecter sur le site ftp de GENBANK dédié aux bactéries en tapant l'adresse suivante dans le navigateur:
ftp://ftp.ncbi.nih.gov/genomes/Bacteria - Cliquer sur le dossier Listeria_innocua
Cliquer avec le bouton droit de la souris sur les fichiers suivants et enregistrer sous format texte (Enregistrer la cible du lien sous ou save link target as ou save link as) dans votre répertoire en les renommant comme ci-dessous :- NC_003212.faa renommé en lin_genes_prot.txt
- NC_003212.ffn renommé en lin_genes_dna.txt
- NC_003212.fna renommé en lin_genome_dna.txt
- Revenir en arrière et cliquer sur le dossier Listeria_monocytogenes
Cliquer avec le bouton droit de la souris sur les fichiers suivants et enregistrer sous format texte (Enregistrer la cible du lien sous ou save link target as ou save link as) dans votre répertoire en les renommant comme ci-dessous :- NC_003210.faa renommé en lmo_genes_prot.txt
- NC_003210.ffn renommé en lmo_genes_dna.txt
- NC_003210.fna renommé en lmo_genome_dna.txt
II. Visualiser les fichiers de séquences
Nous allons afficher successivement le contenu des trois fichiers pour Listeria monocytogenes (lmo) en utilisant le programme Wordpad
- Dans une fenêtre de l'explorateur Windows, cliquer avec le bouton droit sur chacun des programmes et Ouvrir avec Wordpad
- Remarquer le format particulier des fichiers avec la première ligne commençant par un > ; il s'agit d'un fichier en format fasta
- Le génome de Listeria innocua contient 2968 gènes
Le génome de Listeria monocytogenes contient 2846 gènes
- Qui a le plus de gènes ?
- Peut-on en déduire quelle Listeria est dangereuse ?
III. Rechercher les gènes dans les séquences avec EMBOSS
EMBOSS est une suite logicielle d'analyse de séquences. Cette suite logicielle est disponible gratuitement et la plupart des institutions de recherche l'installent sur leur serveur. Les logiciels sont lancés en ligne de commande (dans une fenêtre de Terminal accédant au serveur). Il existe également des interfaces graphiques comme celle mise en place sur le serveur du centre Robert Cedergren : http://anabench.bcm.umontreal.ca/html/EMBOSS/
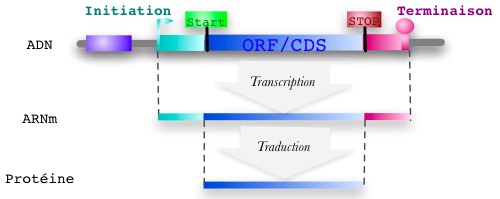
Nous allons rechercher dans une portion de la séquence du génome de Listeria monocytogenes tous les gènes potentiels. On utilisera une règle simple (cf ci-dessous). Cette règle ne permet pas de trouver la totalité du gène (qui commence un peu avant et se termine après) mais la partie qui donnera la protéine. Cette portion est appelée ORF pour "Open Reading Frame" (phase ouverte de lecture) ou CDS pour "Coding sequence" ( séquence codante) lorsque la structure du gène est confirmée.
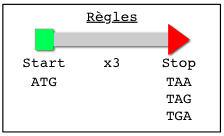 |
 |
- Se connecter sur l'interface graphique de la suite logicielle EMBOSS http://anabench.bcm.umontreal.ca/html/EMBOSS/
- Visualiser la liste des programmes disponibles dans EMBOSS dans la barre de gauche
La liste des programmes disponibles dans EMBOSS est triée par catégories.
Dans la catégorie EDIT, se trouve le programme extractseq pour extraire une portion de la séquence d'ADN.
Dans la catégorie NUCLEIC GENE FINDING se trouve le programme plotorf qui recherche les ORFs. - Extraire, avec le programme extractseq (EDIT) la sous-séquence de 450 000 à 460 000 chez Listeria monocytogenes et la copier dans le fichier lmo_genome_450-460_dna.txt
Utiliser les paramètres suivants (Ne pas modifier les autres) :- [ Browse ]lmo_genome_dna.txt : fichier d'entrée / Input sequence
- Regions to extract: -regions 450000-460000 : on extrait la portion 450000 à 460000
- Lancer le programme en cliquant sur [ run extractseq ]
- Cliquer droit sur le lien Right click to save en haut de la page pour enregistrer le fichier de sortie sous le nom lmo_genome_450-460_dna.txt
- Utilisons le programme plotorf (NUCLEIC GENE FINDING)
Utiliser les paramètres suivants (Ne pas modifier les autres) :- [ Browse ] lmo_genome_450-460_dna.txt : fichier d'entrée / Input sequence
- Lancer le programme en cliquant sur [ run plotorf ]
- Que représentent les barres bleues ?
- Que représentent les six pistes nommées F1, F2, F3, R1, R2, R3 ?
- Sachant qu'un gène bactérien fait en moyenne 1000 bases, combien de gènes devrait-on trouver ?
- Que pensez-vous du résultat obtenu ?
IV. Rechercher les "vrais" gènes avec BLAST
BLAST signifie Basic Local Alignment Search Tool. Cet outil cherche des régions de similarité locale entre les séquences. Le programme compare les séquences de nucléotide ou de protéine à d'autres séquences contenues dans une énorme base de données et calcule des statistiques de significativité
Notre programme a prédit beaucoup de gènes dont beaucoup sont chevauchants. Nous allons extraire toutes les protéines traduites à partir des ORFs prédites et rechercher s'il existe déjà des gènes similaires connus.
Dans un navigateur (firefox, ...)- Se connecter sur l'interface graphique de la suite logicielle EMBOSS http://anabench.bcm.umontreal.ca/html/EMBOSS/
- créer un fichier avec toutes les protéines traduites à partir des ORFs trouvées dansla sous-séquence de 450 000 à 460 000 chez Listeria monocytogenes et la copier dans le fichier lmo_genome_450-460_dna.txt
Avec la commande getorf (NUCLEIC GENE FINDING)
Utiliser les paramètres suivants (Ne pas modifier les autres) :- [ Browse ]lmo_genome_450-460_dna.txt : fichier d'entrée / Input sequence
- Type of output: Translation of regions between START and STOP codons
- Lancer le programme en cliquant sur [ run getorf ]
- Cliquer droit sur le lien Right click to save en haut de la page pour enregistrer le fichier de sortie sous le nom lmo_genome_450-460_ORF_prot.txt
- Dans un navigateur (firefox, ...) : aller sur la page BLAST du NCBI
http://blast.ncbi.nlm.nih.gov/
Sur la page qui s'affiche:- Dans la section Basic BLAST, cliquer sur le lien protein BLAST
- Dans la section Enter Query Sequence, cliquer sur [ Browse ] pour charger le fichier lmo_genome_450-460_ORF_prot.txt
- Dans la section Choose Search Set
- Pour le paramètre Organism, indiquer la valeur 2, cela limitera la recherche de protéines similaires aux bactéries
- Pour l'option Exclude, cocher Uncultured/environmental sample sequences, pour accélérer la recherche
- Dans la section Algorithm parameter (sous le gros bouton bleu [ BLAST ])
Cliquer sur la flèche pour afficher le contenu- Dans la section General Parameters, pour le paramètre Max target sequences, changer la valeur à 10 pour ne pas être submergé par les résultats
- Cliquer sur le bouton bleu [ BLAST ] pour lancer l'outil
La recherche peut prendre plusieurs minutes
La liste des ORFs que nous avons soumise en entrée est dans le menu déroulant. Les ORFs pour lesquelles aucune similarité n'est trouvée sont grises, les autres sont en noir.
- Pourquoi ne trouve-t-on pas de similarité pour certaines ORFs?
- Que remarque-t-on concernant le nombre d'ORFs sans similarité par rapport au nombre d'ORFs avec ?
- Sélectionner le premier résultat positif, la ligne 8 correspondant à l'ORF de 386 acides aminés (386aa). Pourquoi trouve-t-on des similarités chez d'autres espèces ?
- Quelle règle simple pourrait-on trouver pour éviter toutes ces "fausses ORFs" dans nos recherches de gènes?
V. Trouver de l'information sur les génomes avec GENBANK
Le processus qui consiste à rechercher les (vrais) gènes sur un génome et leur associer une fonction biologique est l'annotation.
L'annotation des deux génomes de Listeria qui nous intéressent a déjà été réalisée par des experts de cette espèce. Lorsque l'annotation a été terminée, les équipes de recherche ont publié un article scientifique pour présenter leur travail et ont déposé l'annotation dans les banques de données publiques dont GENBANK fait partie. Nous allons rechercher les informations sur l'annotation de ces bactéries.
Dans un navigateur (firefox, ...)- Allez sur le site Entrez via l'adresse http://www.ncbi.nlm.nih.gov/Entrez/
- Cliquer sur Genome : whole genome sequences dans la colonne de gauche
- Dans la zone de recherche Search for indiquer Listeria[orgn], puis cliquer sur [ Go ]
- Sélectionner les items 5 et 6 : NC_003212 et NC_003210
- En haut de la page, dans le menu Display, sélectionner Overview
La page se recharge automatiquement en affichant les informations pour les deux organismes sélectionnés
- Quelles sont les informations que l'on apprend sur les deux organismes ?
- Cela nous aide-t-il pour savoir si l'un des deux est pathogène ?
- Et en cliquant sur le lien Genome project de la colonne Link du tableau
VI. Rechercher les gènes de virulence (dangereux) avec Artemis ACT
Artemis ACT est un programme de visualisation de comparaison de génomes développé au Sanger Institut. Une version "Java Web Start" de cet outil est disponible sur le site web au JGI (Joint Genome Institut) de Californie avec les comparaisons entre génomes pré-calculées.
Dans un navigateur (firefox, ... )
- Aller sur le site des ressources en microbiologie (IMG : Integrated Microbial Genomes) du
JGI
http://img.jgi.doe.gov/ - Dans le menu en haut de la page, cliquer sur Compare Genomes
- Dans le sous-menu qui s'est affiché, cliquer sur Synteny viewers.
- Une liste d'outils s'affiche, cliquer sur Artemis-ACT.
- Sur la page ACT Genome Selection, sélectionner (en maintenant la touche Ctrl) les
espèces : Listeria innocua Clip 11262 et Listeria monocytogenes EGD-e.
Cliquer sur [ Next ] - Sur la page Pairwise selection, cliquer sur [ Next ].
- Sur la page Contig Reorder - Artemis - ACT,
Dans la colonne Ignore du 2e tableau, cocher la seconde ligne :
2 NC_003383 Listeria innocua Clip11262 plasmid pLI100: NC_003383
Ceci écartera le plasmide de l'analyse
Cliquer sur [ Next ].
Le programme lance des processus ... - Lorsqu'une nouvelle page intitulée Artemis - ACT s'affiche, cliquer sur le bouton [ Run ACT ] qui lancera une application en Java Web Start.
- L'application ACT affiche en haut de la page, le génome de Listeria innocua et en bas
celui de Listeria monocytogenes avec leurs annotations dans les 6 phases de lecture.
S'il existe de fortes similarités entre deux portions de génome, une barre rouge les relie.
Les barres de défilement horizontales tout en haut et tout en bas de la fenêtre permettent de se déplacer sur le génome. Le déplacement est coordonné entre les deux génomes.
Utiliser les barres de défilement horizontal afin d'afficher à l'écran la portion de génome sur laquelle nous avions recherché les ORFs, c'est à dire la portion 450000 à 460000 sur le génome de Listeria monocytogenes.
- Est-ce que nous retrouvons tous les gènes que nous avions prédits (après BLAST) ?
- Sur quel critère peut-on se baser pour trouver les gènes de virulence (qui rendent la bactérie dangereuse, pathogène) ?
- Quels sont les gènes qui pourraient être des gènes de virulence ?
VII. Visualisation de la structure 3D des protéines sélectionnées avec PDB et PyMol
La PDB (Protein Data Bank) est une banque de données de structure tridimensionnelle de molécules.
Dans un navigateur (firefox, ... )
- Se connecter sur le site de la PDB
http://www.pdb.org/ - Dans le champs texte de recherche en haut de page, indiquer 2OMT (la lettre O)
Puis, cliquer sur le bouton Search
La fiche de la structure cristallographique de la protéine sélectionnée et de la Cadherine, son récepteur sur les cellules humaines s'affiche. - Dans le menu à droite, choisissez Download Files puis PDB File (Text).
Le fichier est sauvé sous le nom 2OMT.pdb. - Nous allons utiliser le programme de visualisation moléculaire Pymol afin de l'observer en 3D.
Dans le menu Windows, aller chercher le programme pymol (dans logiciels spécialisé) - Dans la petite fenêtre grise, faites File > Open pour ouvrir le fichier 2OMT.pdb
Puis, dans la fenêtre Pymol viewer, dans le menu à droite, sélectionner :- S(show) et cartoon
- H(hide) et lines
- H(hide) et waters
- C(color) spectrum et rainbow
- Saurez-vous reconnaitre laquelle de ces deux molécules est la Cadherine ?
L'annotation et le métier de bio-informaticien
La conception d'outils pour la recherche de gènes et la manipulation de séquences requiert de bonnes connaissances en algorithmique et en statistique. Ces outils doivent être rapides et donner des résultats pertinents.
L'implémentation des outils afin de les rendre "facilement" utilisables nécessite des aptitudes en programmation et en interface homme/machine.
Bien qu'une partie du travail de l'annotateur soit facilitée par l'amélioration des programmes de recherche de gènes et l'automatisation de suite de processus, l'annotation est une tâche longue qui requiert beaucoup de rigueur et une bonne connaissance de la biologie des organismes.